什么是 KCL 语义模型?
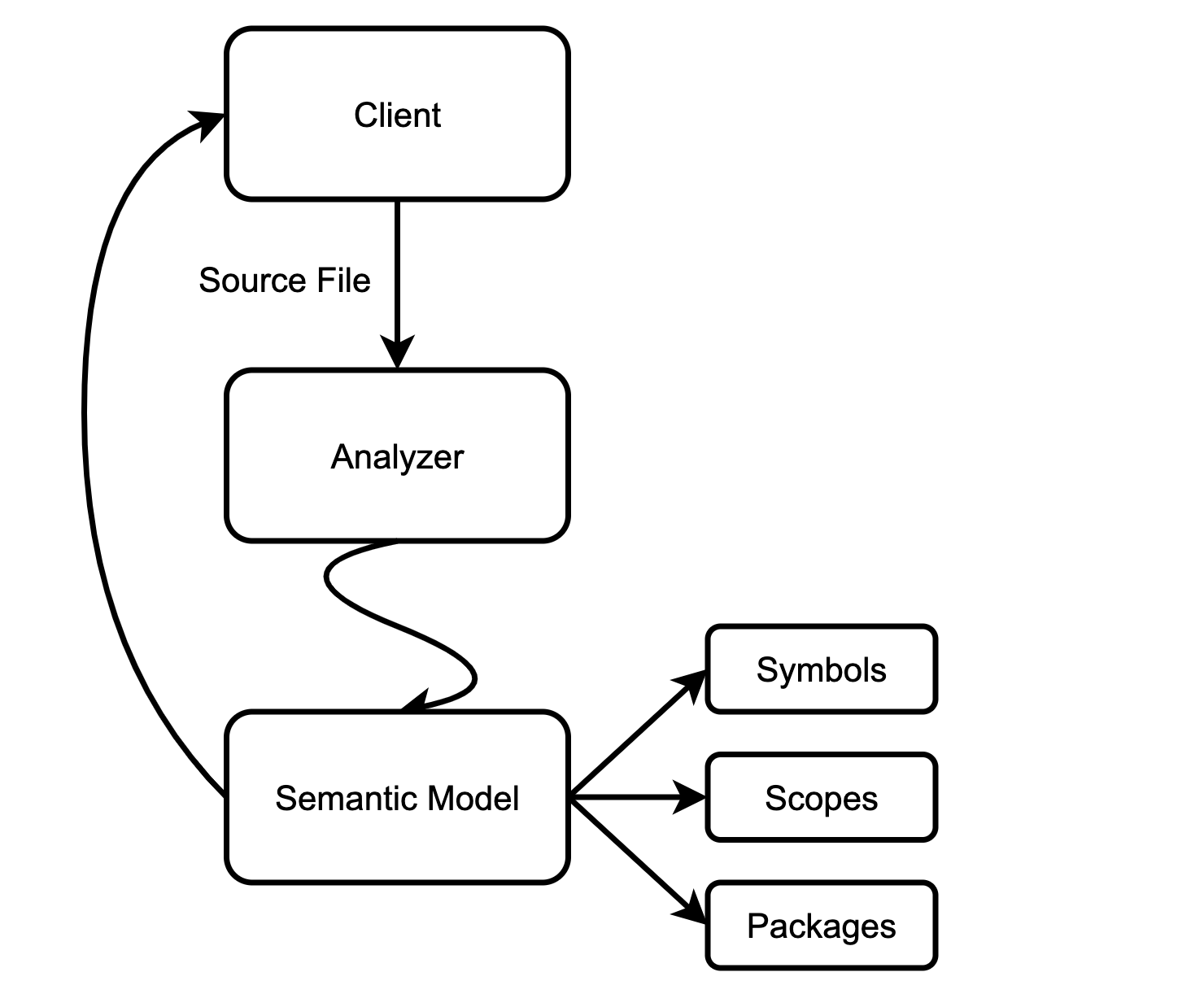
- “语义模型”指的是源代码中出现的模块、函数和类型的内存表示。这种表示是完全“解析”的:所有表达式都有类型(注意,可能存在无法在 KCL 中推导的表达式类型,它们将被定义为 any 类型),并且所有引用都绑定到声明等。
- 客户端可以提交少量的输入数据(通常是对单个文件的更改)并获得新的代码模型来解释更改。
- 底层引擎确保模型是惰性的(按需)和增量计算的,并且可以针对小的变化快速更新。
为什么 KCL 需要新的语义模型?
我们可以先简略地看一下旧语义模型的设计:
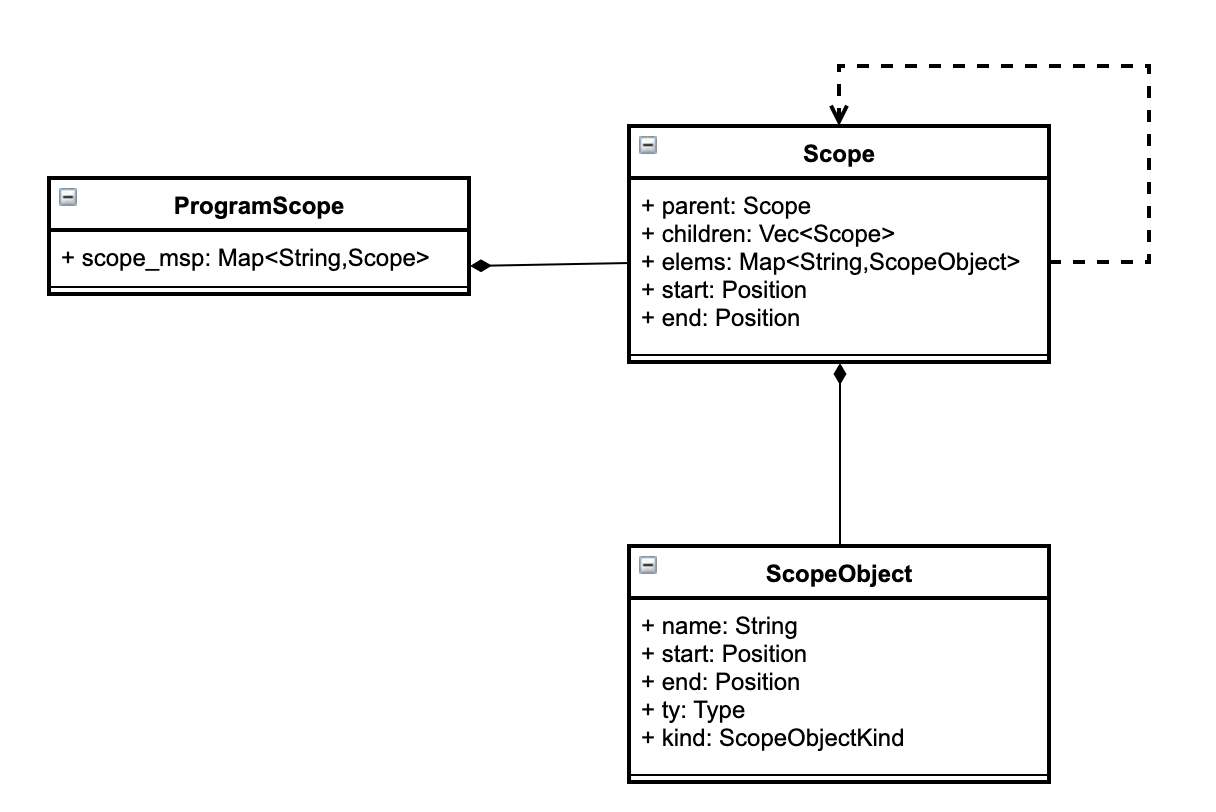 旧语义模型可以简单地看作一个大量作用域的集合,其中不同的作用域内存储了作用域之间的父子节点以及内部包含的符号字符串及对应类型,它可以简单地满足编译器对类型检查和代码生成的需求。但涉及到高级工具链(例如 IDE)这种简单的结构就不足以满足需求了。
举几个典型的 IDE 查询为例:
旧语义模型可以简单地看作一个大量作用域的集合,其中不同的作用域内存储了作用域之间的父子节点以及内部包含的符号字符串及对应类型,它可以简单地满足编译器对类型检查和代码生成的需求。但涉及到高级工具链(例如 IDE)这种简单的结构就不足以满足需求了。
举几个典型的 IDE 查询为例:
- 对应位置下的 ast 节点的类型是什么?
- 所有对当前 ast 节点的引用在哪?(find reference)
- 当前 ast 节点引用了哪个节点?(find definition)
- 当前位置可访问的所有符号?
仅利用旧语义模型,这就要求 IDE 多次遍历 AST 以及进行多次重复计算,可以简单地分析一下旧语义模型的问题,我们可以发现:
- 旧语义模型信息查询较为困难,仅存储了字符串到符号的映射
- 符号之间的关联,符号与作用域之间的关联较弱,导致需要查询相关信息时往往需要遍历所有作用域
- 大量的中间信息在分析过程中被丢弃,未进行缓存,导致多次查询进行重复运算
简而言之,旧语义模型无法满足高级工具链的查询需求,大量信息缺失,另一方面,旧语义模型不支持增量编译,这也降低了工具链的用户体验。
新语义模型的主要思路:Map Reduce
Map Reduce 架构的想法是将分析分为相对简单的索引阶段和单独的完整分析阶段。 索引的核心约束是它基于每个文件运行,索引器获取单个文件的文本,对其进行解析,并吐出有关该文件的一些数据。索引器无法触及其他文件。 完整分析可以读取其他文件,并利用索引中的信息来节省工作量。 这听起来太抽象了,所以让我们看一个具体的例子——Java。在 Java 中,每个文件都以包声明开头。索引器将包的名称与类名连接起来以获得全限定名。它还收集类中声明的方法集、超类和接口的列表等。 每个文件的数据被合并到一个索引中,该索引将全限定名(FQN)映射到类。索引的更新成本很低,当文件修改请求到达时,索引中该文件的贡献将被删除,文件的文本将被更改,索引器将在新文本上运行并添加新的贡献。要做的工作量与更改的文件数量成正比,并且与文件总数无关。 让我们看看如何使用 FQN 索引来快速提供补全。
// File ./mypackage/Foo.java
package mypackage;
import java.util.*;
public class Foo {
public static Bar f() {
return new Bar();
}
}
// File ./mypackage/Bar.java
package mypackage;
public class Bar {
public void g() {}
}
// File ./Main.java
import mypackage.Foo;
public class Main {
public static void main(String[] args) {
Foo.f().
}
}
用户刚刚输入了 Foo.f().,我们需要弄清楚接收者表达式的类型是 Bar,并建议 g 作为补全。
首先,当文件 Main.java 被修改时,我们在这个单个文件上运行索引器:没有任何变化(文件仍然包含具有静态 main 方法的类 Main),因此我们不需要更新 FQN 索引。
接下来,我们需要解析名称 Foo。我们解析文件 Main.java,注意到了 import mypackage.Foo,并且在 FQN 索引中查找 mypackage.Foo 。在索引当中,我们发现 Foo 有一个静态方法 f, 于是我们也成功解析了调用 f()。索引还存储了 f 的返回类型, 但是请注意,索引中存储的是字符串 "Bar",而不是对类 Bar 的直接引用。
这样做的原因在于,Foo.java 中的 import java.util.* 会导致 Bar 可以被推测为 java.util.Bar 或 mypackage.Bar, 索引器并不知道具体是哪一个,因为它只能“看到”文件 Foo.java 的文本。换句话说,虽然索引确实存储了方法的返回类型,但它以未解析的形式存储它们。
下一步是在 Foo.java 的上下文中解析标识符 Bar。这会继续使用 FQN 索引,并且定位到类 mypackage.Bar。于是最后的最后,想要的补全:方法 g 就被我们找到了
完成过程中总共只触及了三个文件。FQN 索引使我们能够完全忽略项目中的所有其他文件。
到目前为止所描述的方法的一个问题是从索引解析类型需要大量的工作。例如,如果 Foo.f 被多次调用,这项工作可能会重复。解决办法是添加缓存。名称解析结果会被记忆,因此只需要进行一次解析。任何更改都会导致缓存完全消失——使用索引,重建缓存的成本并不那么高。
总结一下,第一种方法的工作原理如下:
- 每个文件都被独立且并行地索引,生成一个“存根”—— 指一组可见的顶级声明,具有未解析的类型。
- 所有存根都合并到一个索引数据结构中。
- 名称解析和类型推断主要是在存根基础上进行的。
- 名称解析是惰性的(我们仅在需要时从存根解析类型)并且是记忆的(每种类型仅解析一次)。
- 每次更改时缓存都会完全失效
- 索引是增量更新的:
- 如果编辑没有更改文件的存根,则不需要更改索引。
- 否则,旧索引将被删除,新索引被重新添加
这种方法足够简单并具有出色的性能。大部分工作主要在索引阶段,而这些工作我们可以并行地执行。此架构的两个示例是 IntelliJ 和 Sorbet。 这种方法的主要缺点是它只有在有效时才有效—— 具体而言,并非每种语言都有明确定义的 FQN 概念。但总的来说,设计好模块和名称解析对于语言来说总是好的,具体到目前的情况上,KCL 正好满足这个条件。
新语义模型 Pipeline
新语义模型总体 pipeline 如下:
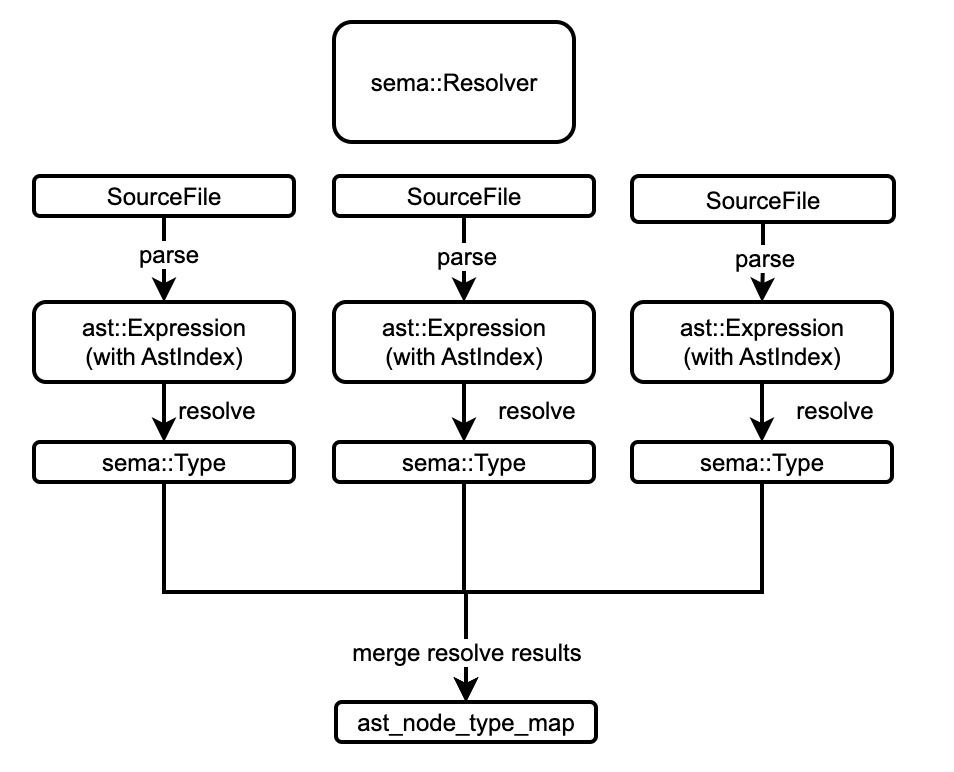
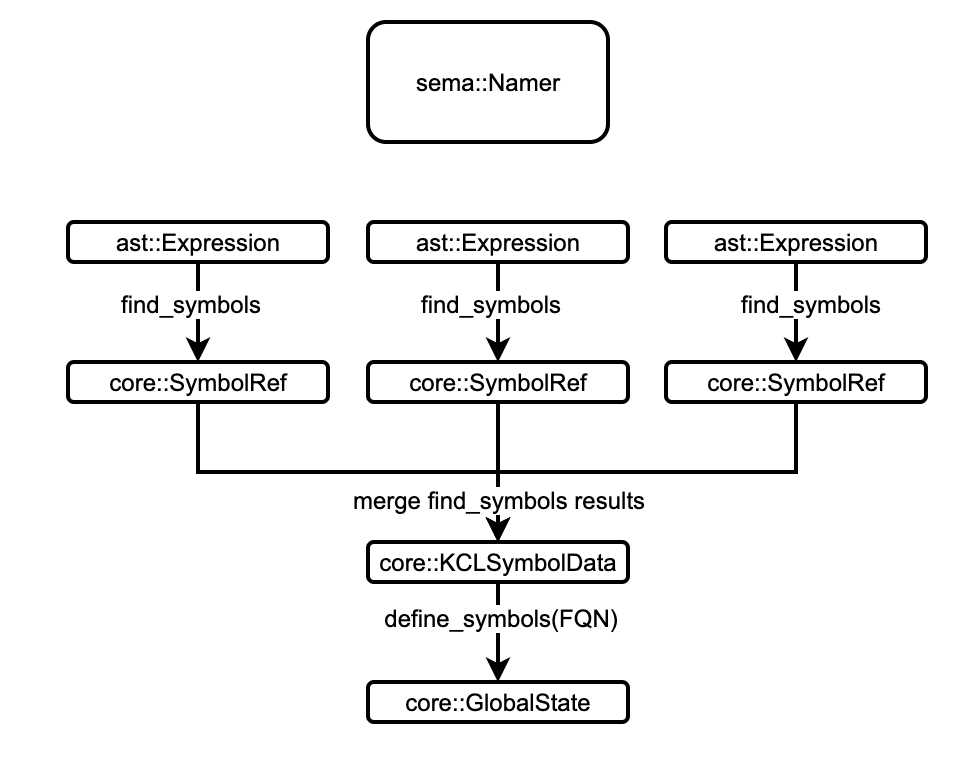
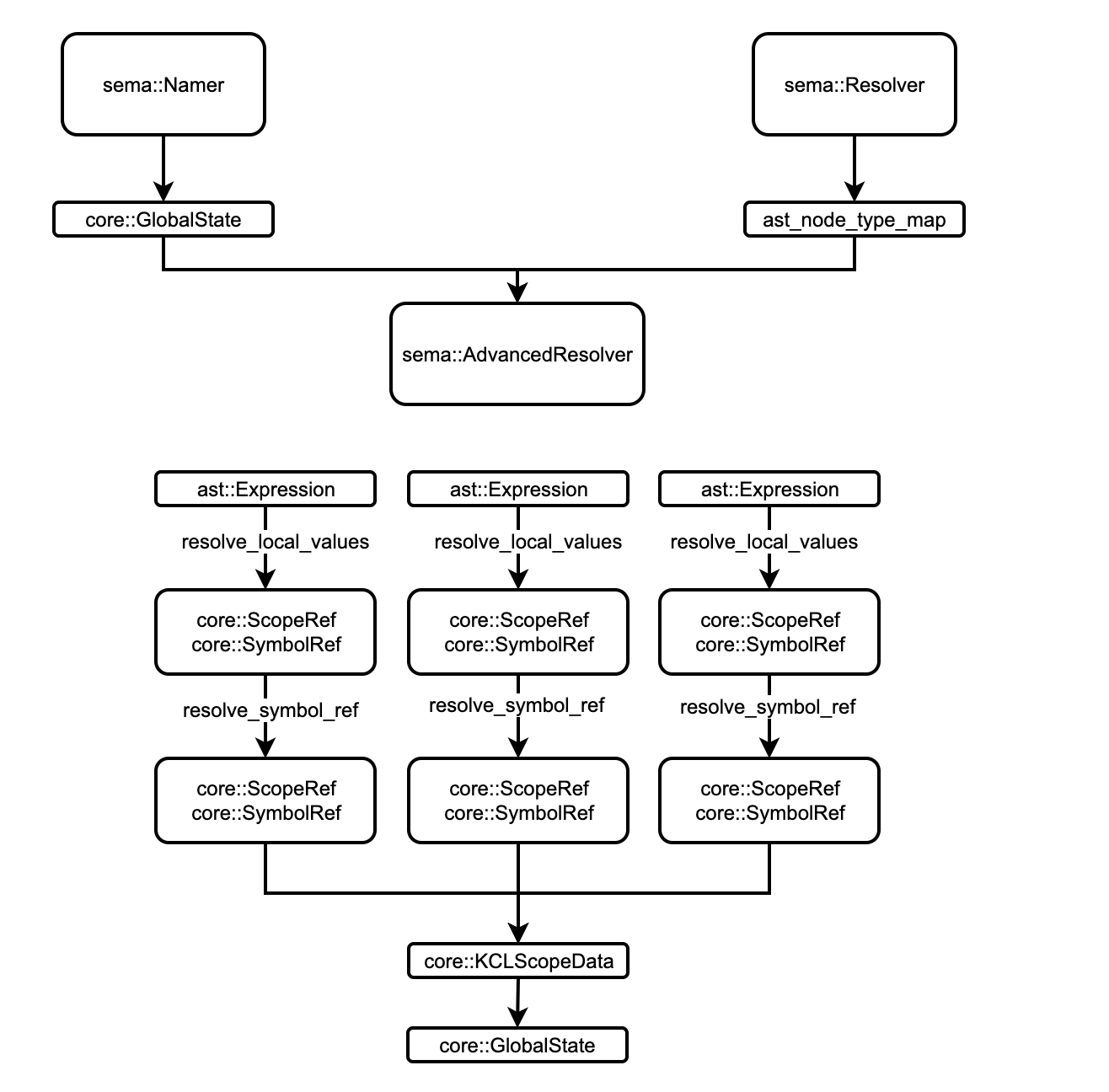 相较于原语义模型分析流程,新语义模型新增了 namer 和 advanced_resolve 两轮 pass,从而在不影响原有编译器流程的情况下增强对高级工具链的支持。
相较于原语义模型分析流程,新语义模型新增了 namer 和 advanced_resolve 两轮 pass,从而在不影响原有编译器流程的情况下增强对高级工具链的支持。
resolver基于文件级别工作,主要涉及GlobalState的初始化,把源代码解析为 AST,并建立 AST 节点到类型的映射以供后面的阶段使用,因此,我们可以缓存单个文件索引的输出,以便在文件内容未更改时完全跳过对该文件的解析。namer的前期阶段也将基于文件级别工作,该阶段收集文件中定义的全局符号,之后将符号基于 FQN 合并,得到唯一一个GlobalState- 基于文件级别意味着我们可以很方便地在前两个阶段进行增量编译
advanced_resolver将遍历 AST 解析局部符号并将符号的引用指向它的定义,同时设置局部作用域的 owner 符号,例如Schema与Package
新语义模型语义数据库:GlobalState
新语义模型的核心结构是 core::GlobalState,工具链主要通过它来完成与编译器的交互及查询。
/// GlobalState is used to store semantic information of KCL source code
#[derive(Default, Debug, Clone)]
pub struct GlobalState {
// store all allocated symbols
symbols: KCLSymbolData,
// store all allocated scopes
scopes: ScopeData,
// store package infomation for name mapping
packages: PackageDB,
// store semantic information after analysis
pub(crate) sema_db: SemanticDB,
}
GlobalState 作为新语义模型的语义数据库被使用,是语义分析后的最终产物,主要包含四个方面的信息:
SymbolData:存储 AST 中的所有符号以及它们对应的语义信息,并维护引用关系ScopeData:存储 AST 中涉及的所有作用域,同时分隔符号,维护符号可见性与作用域嵌套关系PackageDB: 存储包信息,例如包的文件集合,导入信息等SemanticDB: 存储辅助信息,加速查询,如符号的排序和位置缓存等
SymbolData
SymbolData 负责管理符号的分配,存储分配的符号以及相关的语义信息, 在这里我们借用 rust 的 arena 设计来访问相关符号。
#[derive(Default, Debug, Clone)]
pub struct KCLSymbolData {
pub(crate) values: Arena<ValueSymbol>,
pub(crate) packages: Arena<PackageSymbol>,
pub(crate) attributes: Arena<AttributeSymbol>,
pub(crate) schemas: Arena<SchemaSymbol>,
pub(crate) type_aliases: Arena<TypeAliasSymbol>,
pub(crate) unresolved: Arena<UnresolvedSymbol>,
pub(crate) rules: Arena<RuleSymbol>,
pub(crate) symbols_info: SymbolDB,
}
在新语义模型中,我们使用 core::SymbolRef 来表示对一个符号的引用,同时也利用 SymbolRef 来访问 SymbolData 中具体的符号信息。
#[derive(Debug, Clone, Copy, PartialEq, Eq, PartialOrd, Ord, Hash)]
pub struct SymbolRef {
pub(crate) id: generational_arena::Index,
pub(crate) kind: SymbolKind,
}
具体而言,SymbolData 会根据 SymbolRef 的 kind,取出不同类型的 Symbol,并转化为抽象的 trait Symbol。
pub type KCLSymbol = dyn Symbol<SymbolData = KCLSymbolData,
SemanticInfo = KCLSymbolSemanticInfo>;
pub fn get_symbol(&self, id: SymbolRef) -> Option<&KCLSymbol> {
match id.get_kind() {
SymbolKind::Schema => self
.schemas
.get(id.get_id())
.map(|symbol| symbol as &KCLSymbol),
...
}
}
pub trait Symbol {
type SymbolData;
type SemanticInfo;
fn get_sema_info(&self) -> &Self::SemanticInfo;
fn is_global(&self) -> bool;
fn get_range(&self) -> Range;
fn get_owner(&self) -> Option<SymbolRef>;
fn get_definition(&self) -> Option<SymbolRef>;
fn get_name(&self) -> String;
fn get_id(&self) -> Option<SymbolRef>;
fn get_attribute(&self, ...) -> Option<SymbolRef>;
fn has_attribute(&self, ...) -> bool;
fn get_all_attributes(&self, ...) -> Vec<SymbolRef>;
fn simple_dump(&self) -> String;
fn full_dump(&self, data: &Self::SymbolData) -> Option<String>;
}
通过这个 trait,工具链可以轻松地完成符号语义信息以及引用关系的查询。
ScopeData
ScopeData 的设计思路实际上和 SymbolData 类似,存储了不同类型的 Scope 并使用 ScopeRef 访问。
#[derive(Default, Debug, Clone)]
pub struct ScopeData {
/// map pkgpath to root_scope
pub(crate) root_map: IndexMap<String, ScopeRef>,
pub(crate) locals: generational_arena::Arena<LocalSymbolScope>,
pub(crate) roots: generational_arena::Arena<RootSymbolScope>,
}
pub trait Scope {
type SymbolData;
fn get_filename(&self) -> &str;
fn get_parent(&self) -> Option<ScopeRef>;
fn get_children(&self) -> Vec<ScopeRef>;
fn contains_pos(&self, pos: &Position) -> bool;
fn get_owner(&self) -> Option<SymbolRef>;
fn look_up_def(&self, ...) -> Option<SymbolRef>;
fn get_all_defs(&self, ...) -> HashMap<String, SymbolRef>;
fn dump(&self, scope_data: &ScopeData,
symbol_data: &Self::SymbolData) -> Option<String>;
}
SemanticDB
SemanticDB 本质上是语义对象部分语义信息的缓存和整合,它的作用主要是用于加速 GlobalState 内部信息的维护以及查询。
#[derive(Debug, Default, Clone)]
pub struct SemanticDB {
pub(crate) file_sema_map: IndexMap<String, FileSemanticInfo>,
}
#[derive(Debug, Clone)]
pub struct FileSemanticInfo {
pub(crate) filename: String,
pub(crate) symbols: Vec<SymbolRef>,
pub(crate) scopes: Vec<ScopeRef>,
pub(crate) symbol_locs: IndexMap<SymbolRef, CachedLocation>,
pub(crate) local_scope_locs: IndexMap<ScopeRef, CachedRange>,
}
总结
KCL 新语义模型实质上只做了两件事,一是将工具链在应用层做的重复计算下沉至语义层,并设计对应机制简化信息查询,二是将语义分析过程中丢失的信息重新分析并缓存。 这么做主要有几个目的:
- 收拢了计算过程,防止了应用层对编译器语义核心的侵入
- 完善了缓存机制,简化了增量编译的实现,从而加速查询速度
- 简化应用层工具链的开发,同时减少工具链对 Corner Case 的处理,从而提高可维护性
从实践上也基本达到了上述目的,迁移后的 LSP 相关功能的代码量约下降 60%,增量编译后编译速度约提升 500%。