What is the KCL semantic model?
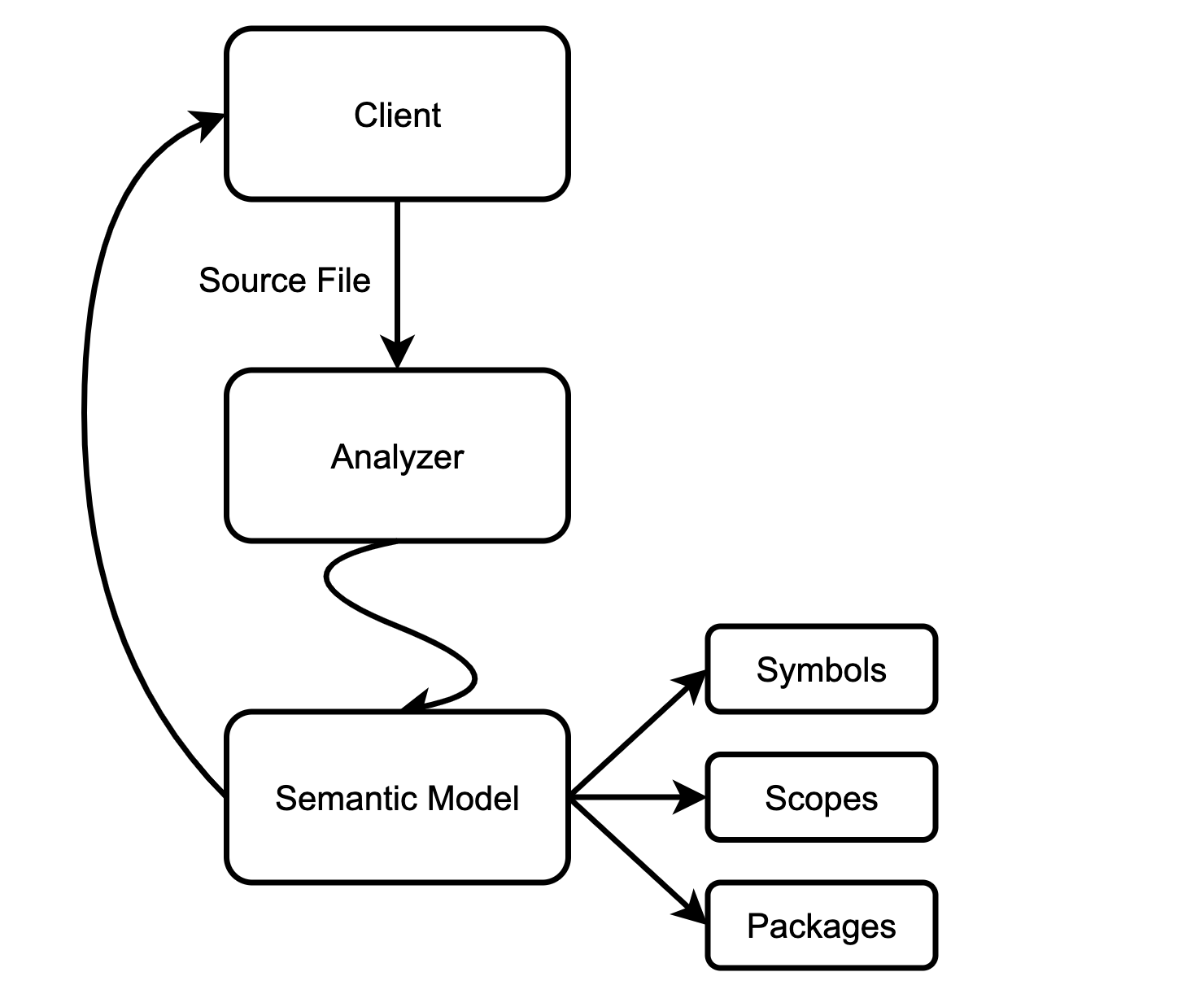
- "Semantic model" refers to the in-memory representation of modules, functions, and types that appear in source code. This representation is fully "resolved": all expressions have types (note that there may be expression types that cannot be deduced in the KCL, they will be defined as any Type), and all references are bound to declarations, etc.
- The client can submit a small amount of input data (typically changes to a single file) and get a new code model to explain the changes.
- The underlying engine ensures that the model is Lazy (on demand) and incremental computational and can be updated quickly for small changes.
Why does KCL need a new semantic model?
First, we can take a brief look at the design of the old semantic model: 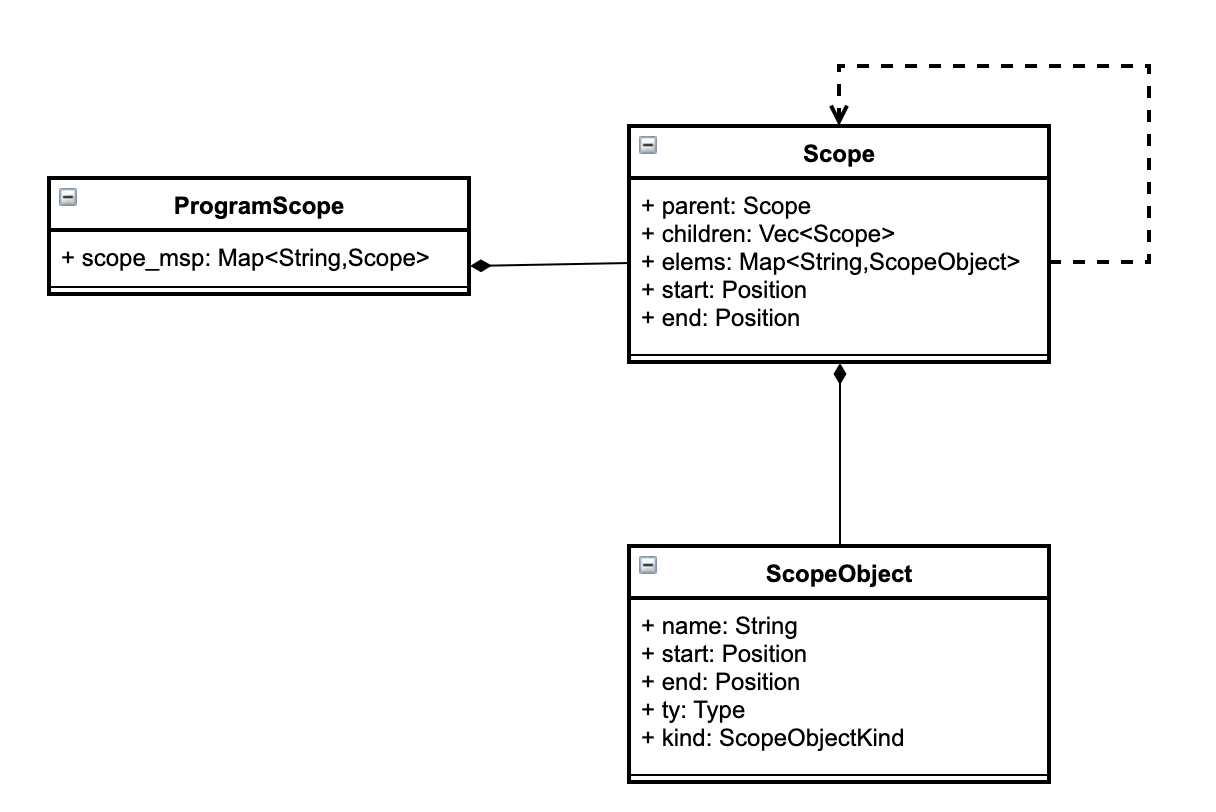 the old semantic model can be simply regarded as a collection of a large number of scopes, in which different scopes store the parent-child nodes between the scopes, as well as the symbol strings and corresponding types contained therein. It can simply meet the requirements of the compiler for type checking and code generation. But a simple structure involving an advanced tool chain, such as an IDE, is not sufficient. A few examples of typical IDE queries:
the old semantic model can be simply regarded as a collection of a large number of scopes, in which different scopes store the parent-child nodes between the scopes, as well as the symbol strings and corresponding types contained therein. It can simply meet the requirements of the compiler for type checking and code generation. But a simple structure involving an advanced tool chain, such as an IDE, is not sufficient. A few examples of typical IDE queries:
- What is the type of the AST node under the corresponding position?
- Where are all the references to the current AST node? (find reference)
- Which node is referenced by the current AST node? (find definition)
- All symbols accessible at the current position?
Only the old semantic model is used, which requires the IDE to traverse the AST for many times and perform repeated calculations. We can simply analyze the problems of the old semantic model, and we can find that:
- The old semantic model was more difficult to query information, and only stored the mapping from character string to symbol
- The association between symbols and the weak association between symbols and scopes often leads to the need to traverse all scopes when querying for relevant information
- A large amount of intermediate information is discarded in the analysis process and is not cached, resulting in repeated operations for multiple queries.
In short, the old semantic model can not meet the query needs of the advanced tool chain, and a lot of information is missing. On the other hand, the old semantic model does not support incremental compilation, which also reduces the user experience of the tool chain.
Main Idea: Map Reduce
The idea of the Map Reduce architecture is to split the analysis into a relatively simple indexing phase and a separate full analysis phase.
The core constraint of indexing is that it runs on a per-file basis, with the indexer taking the text of a single file, parsing it, and spitting out some data about that file. The indexer cannot touch other files. Full analysis can read other files and use the information in the index to save effort.
This sounds too abstract, so let's look at a concrete example-Java. In Java, each file begins with a package declaration. The indexer concatenates the package name with the class name to get the fully qualified name. It also collects the set of methods declared in the class, the list of superclasses and interfaces, and so on.
The data for each file is merged into an index that maps fully qualified names (FQNs) to classes. The index is inexpensive to update, and when a file modification request arrives, the contribution to that file in the index is removed, the text of the file is changed, and the indexer runs on the new text and adds the new contribution. The amount of work to be done is proportional to the number of files changed and is independent of the total number of files.
Let's see how to use the FQN index to quickly provide completion.
// File ./mypackage/Foo.java
package mypackage;
import java.util.*;
public class Foo {
public static Bar f() {
return new Bar();
}
}
// File ./mypackage/Bar.java
package mypackage;
public class Bar {
public void g() {}
}
// File ./Main.java
import mypackage.Foo;
public class Main {
public static void main(String[] args) {
Foo.f().
}
}
The user just entered Foo.f(). We need to clarify that the receiver expression type is Bar and suggest g as completion.
Firstly, when the file Main.java is modified, we run the indexer on this individual file without any changes (the file still contains the class Main with static main methods), so we do not need to update the FQN index.
Next, we need to resolve the name Foo. We parsed the file Main.java and noticed the import mypackage.Foo and search for mypackage.Foo in the FQN index. In the index, we found that Foo has a static method f, so we successfully resolved the call to f(). The index also stores the return type of f, but please note that the index stores the string Bar instead of a direct reference to the class Bar.
The reason for doing this is that the import java.util.* in Foo.java can cause the Bar to be inferred as either java.util.Bar' or mypackage.Bar, the indexer doesn't know which one it is because it can only "see" the text of the file Foo.java. In other words, although the index does store the return types of methods, it stores them in an unresolved form.
The next step is to parse the identifier Bar in the context of Foo.java. This will continue to use FQN indexing and navigate to class mypackage.Bar. So in the end, we found the method g that we wanted to complete.
During the completion process, only three files were touched upon in total. The FQN index allows us to completely ignore all other files in the project.
One problem with the methods described so far is that parsing types from indexes requires a lot of work. For example, if Foo.f' is called multiple times, this task may be repeated. The solution is to add a cache. The name resolution result will be remembered, so only one resolution is required. Any changes will cause the cache to completely invalid - the cost of rebuilding the cache using indexes is not that high.
To summarize, the working principle of the first method is as follows:
- Each file is independently and parallelly indexed, generating a "stub" - a set of visible top-level declarations with unresolved types.
- Merge all stubs into one indexed data structure.
- Name parsing and type inference are mainly based on stubs.
- Name resolution is lazy (we only parse types from stubs when needed) and memory based (each type is parsed only once).
- The cache will be completely invalidated every time a change is made
- The index is incrementally updated:
- If the editor has not changed the stub of the file, there is no need to change the index.
- Otherwise, the old index will be deleted and the new index will be added again
This method is simple enough and has excellent performance. Most of the work is mainly in the indexing phase, and we can execute these tasks in parallel. Two examples of this architecture are IntelliJ And Sorbet.
The main drawback of this method is that it is only effective when it is effective - specifically, not every language has a clearly defined concept of FQN. But overall, designing modules and name parsing is always good for languages, and specifically, in the current situation, KCL just meets this condition.
New Semantic Model Pipeline
The overall pipeline of the new semantic model is as follows:
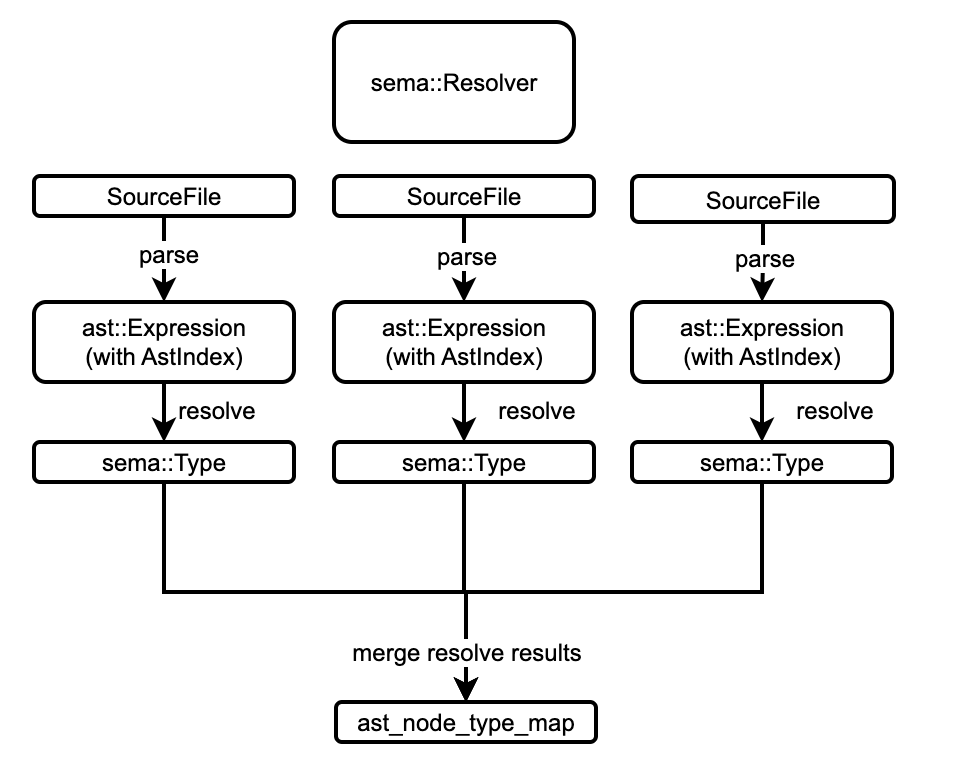
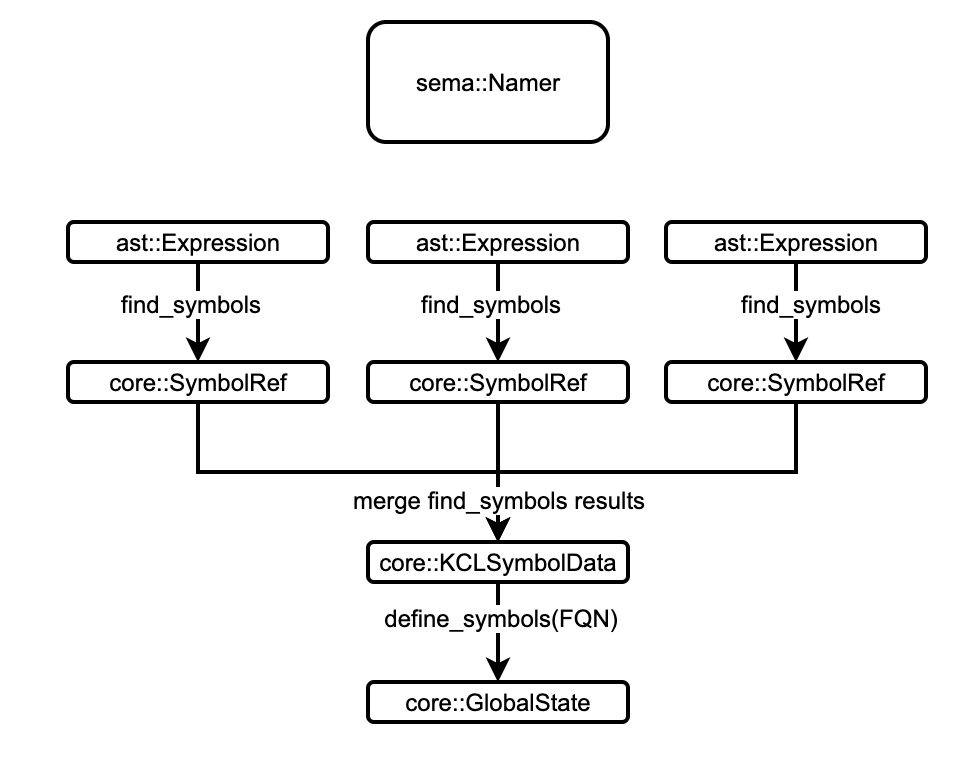
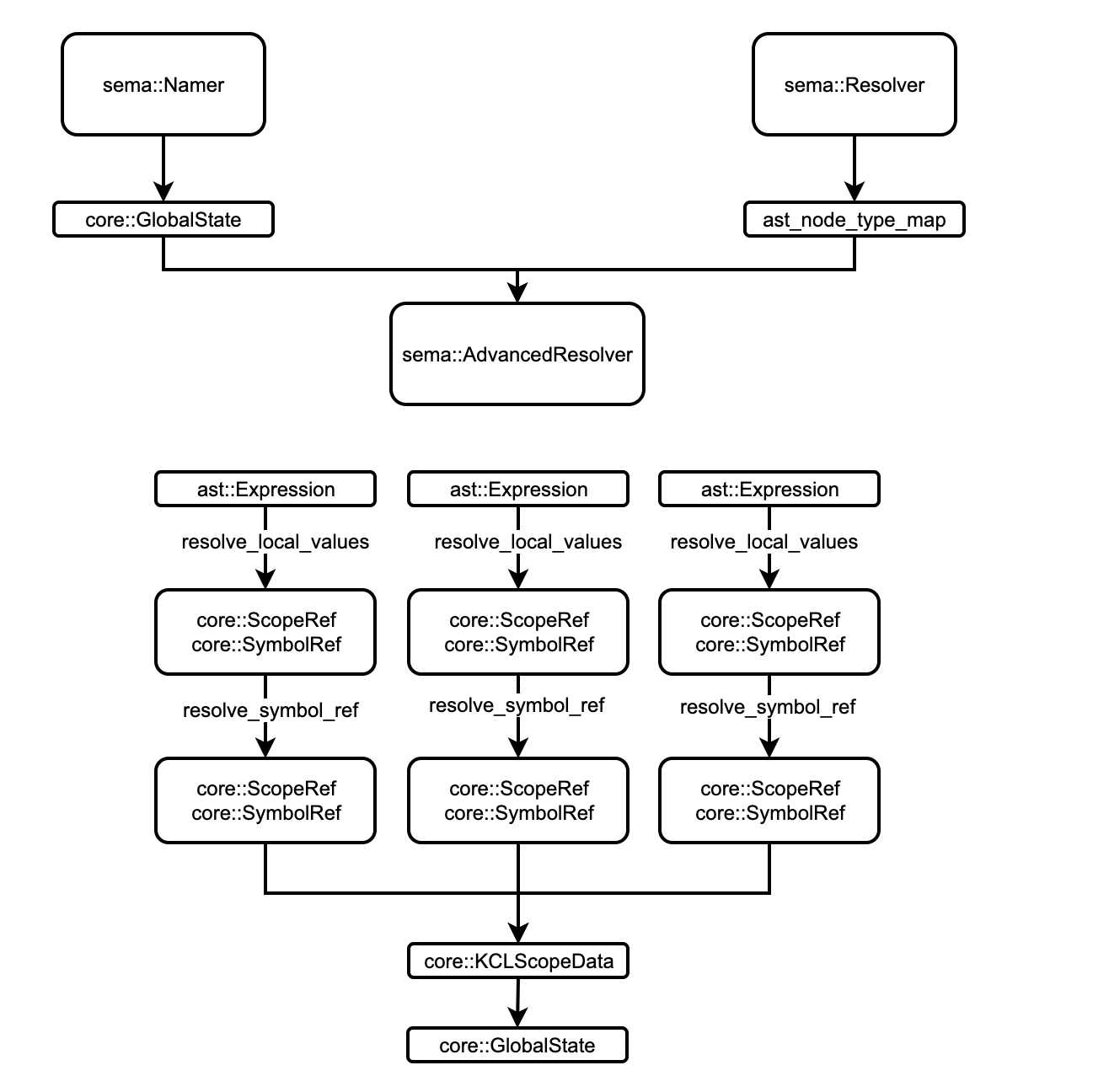 Compared with the analysis process of the original semantic model, the new semantic model adds two rounds of pass, namer and advanced _ resolve, so as to enhance the support for the advanced tool chain without affecting the original compiler process.
Compared with the analysis process of the original semantic model, the new semantic model adds two rounds of pass, namer and advanced _ resolve, so as to enhance the support for the advanced tool chain without affecting the original compiler process.
- The
resolveris based on file level work, mainly involving the initialization of theGlobalState, parsing the source code into AST, and establishing the mapping of AST nodes to types for later stages to use. Therefore, we can cache the output of a single file index to completely skip parsing the file when its content has not changed. - The early stage of
namerwill also be based on file level work, which collects global symbols defined in the file, and then merges the symbols based on FQN to obtain a uniqueGlobalState- Based on file level, it means we can easily perform incremental compilation in the first two stages
advanced_resolverwill traverse the AST to resolve local symbols and point symbol references to their definitions, while setting the owner symbol for the local scope, such asSchemaandPackage
Semantic Database: GlobalState
The core structure of the new semantic model is core::GlobalState that the tool chain mainly uses it to complete the interaction and query with the compiler.
/// GlobalState is used to store semantic information of KCL source code
#[derive(Default, Debug, Clone)]
pub struct GlobalState {
// store all allocated symbols
symbols: KCLSymbolData,
// store all allocated scopes
scopes: ScopeData,
// store package infomation for name mapping
packages: PackageDB,
// store semantic information after analysis
pub(crate) sema_db: SemanticDB,
}
GlobalState is used as a semantic database for the new semantic model and is the final product of semantic analysis, mainly containing four aspects of information:
SymbolData: stores all symbols in the AST and their corresponding semantic information, and maintain the reference relationship.ScopeData: stores all scopes involved in the AST, while separating symbols, maintaining symbol visibility and scope nesting relationshipsPackageDB: stores package information, such as a collection of files for the package, import information, and so on.SemanticDB: stores auxiliary information to speed up queries, such as symbol sorting and position caching.
SymbolData
SymbolData is responsible for managing the allocation of symbols and storing the allocated symbols and related semantic information. Here we borrow the arena design of rust to access the relevant symbols.
#[derive(Default, Debug, Clone)]
pub struct KCLSymbolData {
pub(crate) values: Arena<ValueSymbol>,
pub(crate) packages: Arena<PackageSymbol>,
pub(crate) attributes: Arena<AttributeSymbol>,
pub(crate) schemas: Arena<SchemaSymbol>,
pub(crate) type_aliases: Arena<TypeAliasSymbol>,
pub(crate) unresolved: Arena<UnresolvedSymbol>,
pub(crate) rules: Arena<RuleSymbol>,
pub(crate) symbols_info: SymbolDB,
}
In the new semantic model, we use core::SymbolRef to represent a reference to a symbol, and also use SymbolRef to access SymbolData for the specific symbol information.
#[derive(Debug, Clone, Copy, PartialEq, Eq, PartialOrd, Ord, Hash)]
pub struct SymbolRef {
pub(crate) id: generational_arena::Index,
pub(crate) kind: SymbolKind,
}
Specifically, Symbols with different types will be taken out from SymbolData according to SymbolRef::kind and converted to abstract trait Symbol.
pub type KCLSymbol = dyn Symbol<SymbolData = KCLSymbolData,
SemanticInfo = KCLSymbolSemanticInfo>;
pub fn get_symbol(&self, id: SymbolRef) -> Option<&KCLSymbol> {
match id.get_kind() {
SymbolKind::Schema => self
.schemas
.get(id.get_id())
.map(|symbol| symbol as &KCLSymbol),
...
}
}
pub trait Symbol {
type SymbolData;
type SemanticInfo;
fn get_sema_info(&self) -> &Self::SemanticInfo;
fn is_global(&self) -> bool;
fn get_range(&self) -> Range;
fn get_owner(&self) -> Option<SymbolRef>;
fn get_definition(&self) -> Option<SymbolRef>;
fn get_name(&self) -> String;
fn get_id(&self) -> Option<SymbolRef>;
fn get_attribute(&self, ...) -> Option<SymbolRef>;
fn has_attribute(&self, ...) -> bool;
fn get_all_attributes(&self, ...) -> Vec<SymbolRef>;
fn simple_dump(&self) -> String;
fn full_dump(&self, data: &Self::SymbolData) -> Option<String>;
}
hrough this trait, the tool chain can easily complete the query of symbol semantic information and reference relationship.
ScopeData
The design idea of ScopeData is actually similar to SymbolData, it stores Scope with different types and using ScopeRef to access them.
#[derive(Default, Debug, Clone)]
pub struct ScopeData {
/// map pkgpath to root_scope
pub(crate) root_map: IndexMap<String, ScopeRef>,
pub(crate) locals: generational_arena::Arena<LocalSymbolScope>,
pub(crate) roots: generational_arena::Arena<RootSymbolScope>,
}
pub trait Scope {
type SymbolData;
fn get_filename(&self) -> &str;
fn get_parent(&self) -> Option<ScopeRef>;
fn get_children(&self) -> Vec<ScopeRef>;
fn contains_pos(&self, pos: &Position) -> bool;
fn get_owner(&self) -> Option<SymbolRef>;
fn look_up_def(&self, ...) -> Option<SymbolRef>;
fn get_all_defs(&self, ...) -> HashMap<String, SymbolRef>;
fn dump(&self, scope_data: &ScopeData,
symbol_data: &Self::SymbolData) -> Option<String>;
}
SemanticDB
SemanticDB is essentially the caching and integration of partial semantic information of semantic objects. Its main function is to accelerate the maintenance and querying of internal information in GlobalState.
#[derive(Debug, Default, Clone)]
pub struct SemanticDB {
pub(crate) file_sema_map: IndexMap<String, FileSemanticInfo>,
}
#[derive(Debug, Clone)]
pub struct FileSemanticInfo {
pub(crate) filename: String,
pub(crate) symbols: Vec<SymbolRef>,
pub(crate) scopes: Vec<ScopeRef>,
pub(crate) symbol_locs: IndexMap<SymbolRef, CachedLocation>,
pub(crate) local_scope_locs: IndexMap<ScopeRef, CachedRange>,
}
Summary
The new semantic model of KCL essentially only does two things, one is to sink the repeated calculation of the tool chain in the application layer to the semantic layer, and design a corresponding mechanism to simplify the information query, and the other is to re-analyze and cache the information lost in the semantic analysis process. There are several main purposes for doing so:
- The calculation process is gathered, and the intrusion of the application layer into the semantic core of the compiler is prevented
- The cache mechanism is improved, and the implementation of incremental compilation is simplified, so that the query speed is accelerated.
- Improve maintainability by simplifying the development of the application layer tool chain and reducing the handling of Corner Cases by the tool chain
In practice, the above objectives are basically achieved. After migration, the code volume of LSP related functions is reduced by about 60%, and the compilation speed is increased by about 500% after incremental compilation.